Turn every question into a governed, reusable automation.
While others stop at data movement, Keboola enables AI pipeline creation, orchestration, and complete audit—all in one unified platform.
Available on
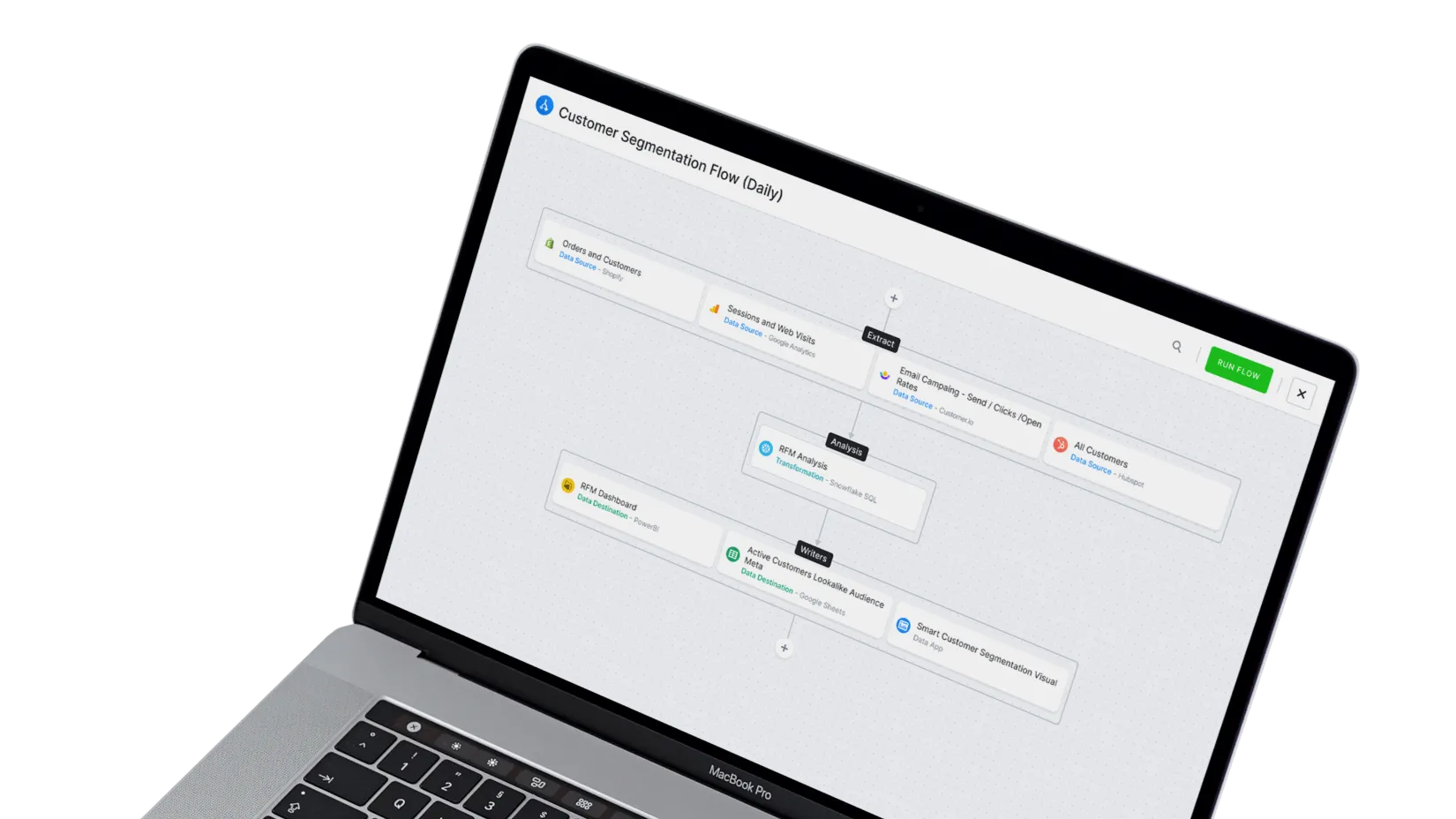


Make AI Work for the Business, Not Just the Lab
Free Engineering from the Backlog
Eliminate Shadow AI for Good
Turn AI into ROI
Keboola AI & Data Platform
Built from the ground up to support autonomous AI operations with enterprise-grade reliability and security.
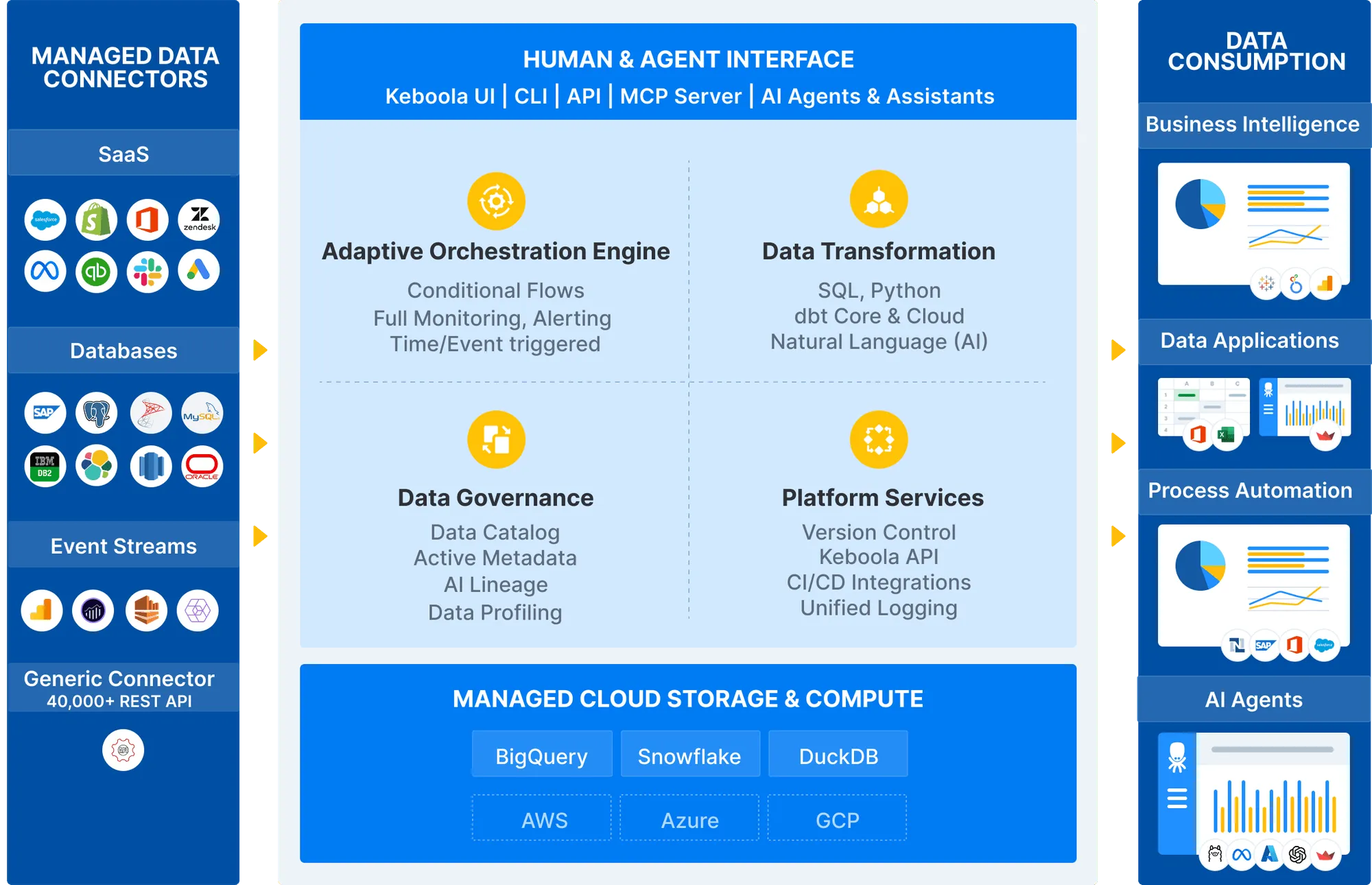

Platform Capabilities
Everything you need to build, run, and govern AI-powered data workflows at enterprise scale.
Ingest from 700+ sources and orchestrate complex workflows. No fragile scripts or hidden bottlenecks.
- End-to-end data pipeline for AI/BI
- Full version control & branching
- Safe experimentation in SQL/Python workspaces
Use Our MCP Server to build end-to-end data workflows with natural language or AI agents such as:
- Keboola AI Assistant
- Cursor, Windsurf or Devin
- Claude, ChatGPT
Compliance, cost monitoring, and policy enforcement are automatic—so you can scale securely without sacrificing agility.
- Full cost and usage monitoring (FinOps)
- Complete telemetry data about every job
- Multiproject environment for access separation
What sets Keboola apart
from other Data platforms
End-to-End Data Platform Without the Overhead
Run your entire data lifecycle—ingestion to AI delivery—on one governed platform, replacing dozens of tools and eliminating integration headaches.
Operationalize AI Across the Business
Turn any dataset into AI-powered applications and automations—safely, predictably, and at scale.

Deploy Anywhere, Stay in Control
Run Keboola on AWS, Azure, GCP, or your private cloud—without lock-in, with seamless integration.
Freedom to Build, Your Way — With AI at the Core
Whether you're coding in Python or SQL, building flows in UI, or prompting AI to generate pipelines—Keboola adapts to your workflow.
Active Metadata to Power Observability
Trace every dataset, transformation, and output instantly—across the entire platform—for compliance, debugging, and trust.
Real Customers. Real Results.

How Home Credit Consolidated Finances Across 9 Countries with Keboola
With 25M+ customers and 62M credit decisions across 9 countries, Home Credit uses Keboola to power global financial consolidation and analytics.


How Česká spořitelna Empowered 70+ Teams with Self-Service Analytics
Czech Republic's largest bank transformed how business teams access and analyze data, empowering 70+ teams with self-service analytics.


How Brix Centralized Data Across a Portfolio of QSR Brands
BRIX Holdings unified data from 350+ restaurant locations across multiple QSR brands to drive operational excellence and faster decision-making.


How Carvago Processes 5.5M Car Ads Daily with Keboola
Europe's online used car marketplace built a data platform that processes millions of car listings in real-time, going from idea to product in just 3 months.

Trusted by 1,000+ companies
.png)
.png)
.png)
.png)

At Keboola, security and privacy aren't features—they're our foundation.
We meet the strictest industry standards so you can innovate with confidence. Your data stays protected, compliant, and under your control — always.
GDPR
EU General Data Protection Regulation
HIPAA
Health Insurance Portability and Accountability Act
SOC 2
Service Organization Control Type 2
FAQs
What's New
Latest insights from the Keboola blog

From 50 Spreadsheets to One Source of Truth
A PE Leader's Guide to Portfolio Monitoring Automation and Multi-Entity Financial Consolidation. How PE Operating Partners and portfolio CFOs move from 50 spreadsheets to one live, automated view — without replacing a single ERP.

The PE CFO Playbook: Your First 100 Days, Data-First

The 8-12 Week PE Financial Data Foundation Framework
A deployable implementation guide for PE Operating Partners and incoming CFOs. From acquisition close to live, automated portfolio visibility — without replacing a single ERP.


