Tag, Track, and Certify Data in One Metadata Layer
Every execution, every table, every user — captured as active metadata and unified for governance, observability, and automation.
See Keboola Metadata in action
Complete Pipeline Observability
A single pane of glass into every job, transformation, and data flow. Detect failures instantly, trace errors to their source, and optimize performance.
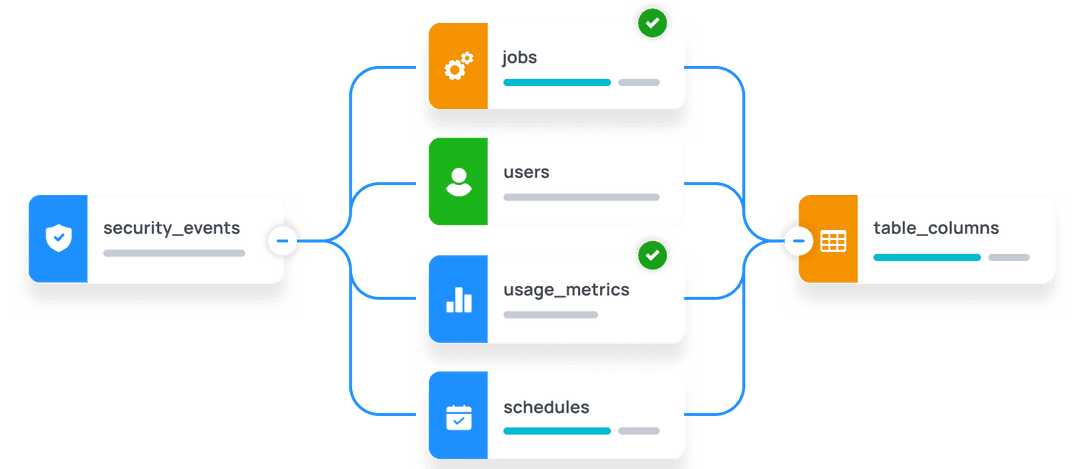
Learn MoreTag, Classify, and Certify Every Dataset
1,050+ attributes tracked across every table, bucket, and flow — ownership, sensitivity, freshness, quality — turning raw data into certified products.
Learn MoreAudit Trails & Compliance Built In
50+ types of security events captured automatically — from logins and token creation to data exports. Push events to SIEMs for centralized monitoring.
Learn MoreSee Every User, Every Action
Monitor organization-wide activity with full user attribution — track logins, configuration changes, and data access patterns across all projects.
Learn MoreFrom Cost Visibility to True TCO
Enable a 'Zero IT Budget' model — track true usage, attribute spend to projects and departments, and re-invoice based on actual consumption.
Learn MoreThe Business Impact of Active Metadata
Compliance, Built In
One Platform, No Sprawl
Zero IT Budget
Activate Your Metadata
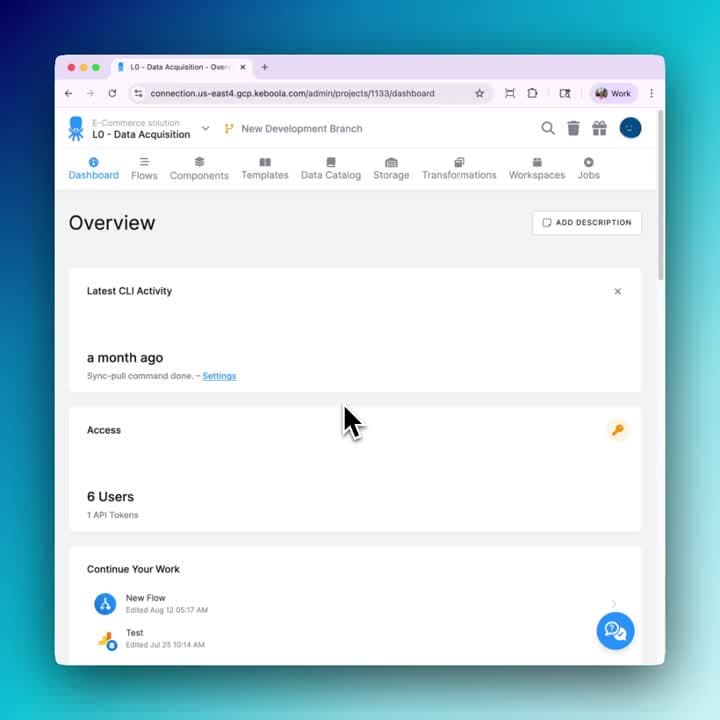
Data Catalog
Transform raw datasets into certified data products
Transform raw datasets into certified data products with full metadata context — discover, share, and reuse trusted data across teams with governance baked in.
Learn More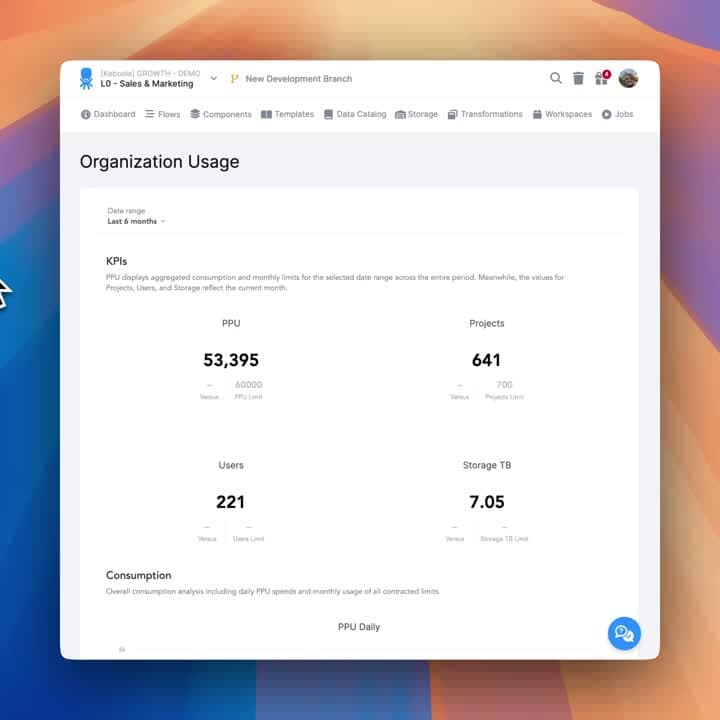
Activity Center
Turn metadata into a live control tower
Turn metadata into a live control tower — monitor spend, performance, and security across all your projects in one unified view.
Learn More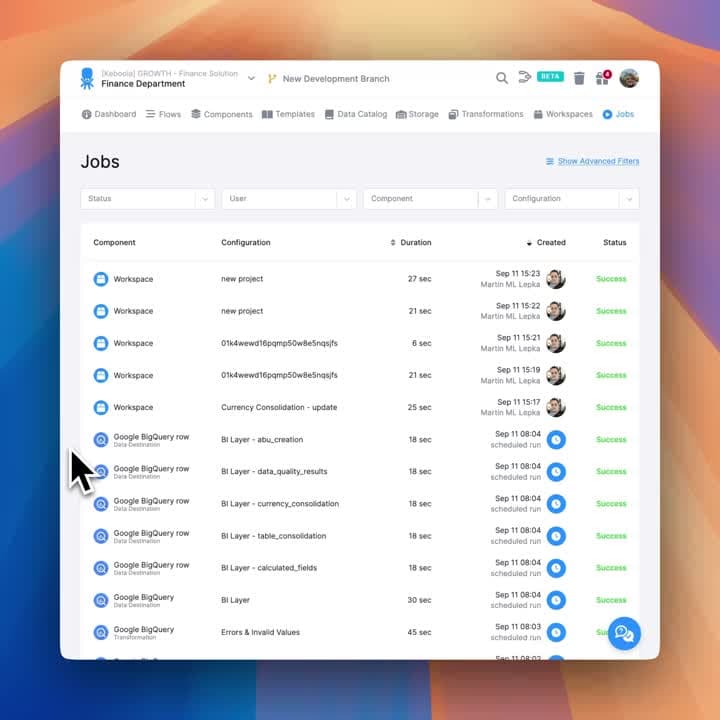
Data Lineage
Track every dataset from source to dashboard
Track every dataset and dependency from source to dashboard for compliance and trust — end-to-end clarity for every pipeline.
Get in TouchWhat sets Keboola apart
from other Data platforms
End-to-End Data Platform Without the Overhead
Run your entire data lifecycle — ingestion to AI delivery — on one governed platform, replacing dozens of tools.
Operationalize AI Across the Business
Turn any dataset into AI-powered applications and automations — safely, predictably, and at scale.

Deploy Anywhere, Stay in Control
Run Keboola on AWS, Azure, GCP, or your private cloud.
Freedom to Build, Your Way
Python, SQL, UI, or AI — Keboola adapts to your workflow.
Active Metadata to Power Observability
Trace every dataset and output instantly for compliance and trust.
Recognized by Industry Leaders
Keboola is consistently rated as a top data platform by G2 reviewers.




What Our Customers Say
“The successful implementation of Keboola was crucial to becoming a digital company, propelling us forward with better business information.”
Thilo Kusch
Group CFO, P3 Logistic Parks
“The Keboola MCP Server generated an RFM segmentation pipeline end-to-end, then built me a dashboard automatically from a simple request.”
Marcus Wong
Senior Manager, Cuesta Partners
“We wanted teams to access their own data and perform analysis timely without relying on IT for data delivery.”
John Howard
Director of IT, Brix Holdings
“Keboola's solution has transformed our approach to data, making it crucial to our daily operations.”
Jakub Zalio
Group CTO, Creditinfo Group


