
Make All Your Data Ready for AI
From integration to reverse-ETL — with SQL & Python workspaces, Dev/Prod mode, native dbt, and more.
Transform your data the way you want it
Start with a blank canvas, reuse shared code, or use AI agents to scaffold logic.
Connect Cursor or other AI agents to Keboola MCP Server to scaffold SQL or Python transformations in natural language.
- Build and update pipelines with prompts
- Explore datasets and model them
- Schedule recurring jobs and orchestrations
Paste your code directly in the platform. Keboola handles orchestration and deployment — choose your backend and start coding.
- Choose transformation backend type and size
- Build logic in SQL or Python isolated workspaces
- Automate with the visual Flow Builder
Run dbt wherever it makes sense: Core, Cloud, or Hybrid. Orchestrate in full workflow context with built-in lineage.
- Run tests and promote to production
- Orchestrate in full workflow context
- Built-in Metadata and Lineage



Beyond ETL: A Complete Toolset for Engineers
Data Sandbox
Dev/Prod Mode & Branching
Version Control with AI
What sets Keboola apart
from other ETL/ELT tools
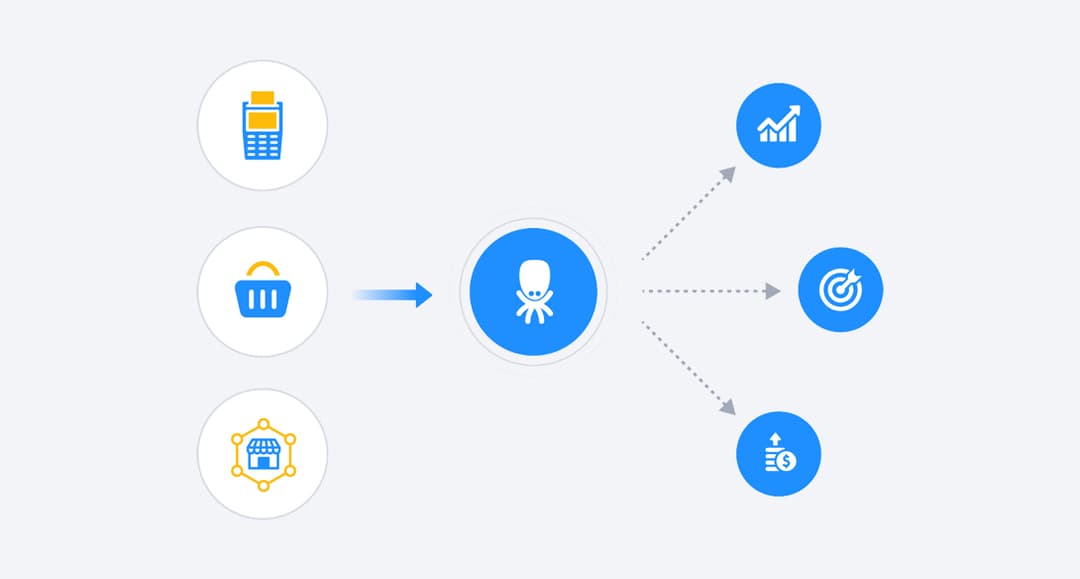
Democratise Insights Across the Company
Enable governed self-service for business teams and unlock a true ROI multiplier — without waiting on IT.
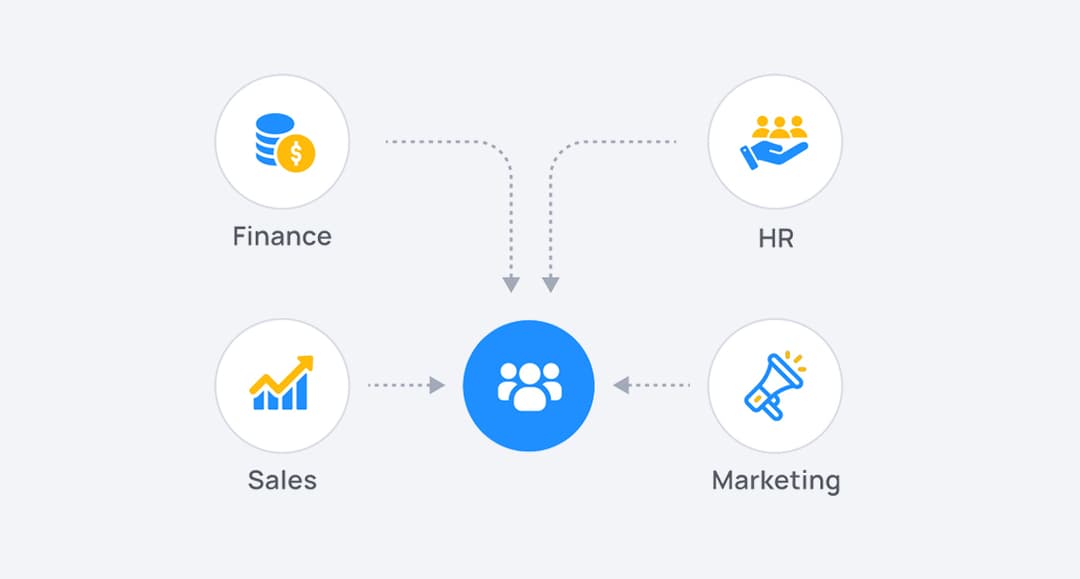
Finally, a Truly Unified Platform
Keboola can replace up to 50% of your SaaS data tools — freeing your engineers to focus on high-impact projects.

Ecosystem Integration
Keboola integrates with everything: databases, SaaS apps, files, APIs, and business processes. Trigger Slack alerts, update CRMs, or call any API.
80% Less Maintenance
Automated operations free up engineering time — spend less time troubleshooting, more time innovating.
Enterprise-Grade Reliability in the AI Era
In a world where AI agents can feel unpredictable, Keboola delivers deterministic, governed execution you can trust.
All the data integrations you'll ever need in one place
700+ connectors for databases, SaaS apps, files, and APIs.


